GEP-0038: Autoscaling PersistentVolumeClaims
Table of Contents
- GEP-0038: Autoscaling PersistentVolumeClaims
Summary
Gardener currently uses a one-size-fits-all strategy for the volumes of its observability workloads which can be problematic due to both over-provisioning (generating extra costs) and under-provisioning (missing observability signals).
This document proposes a way to resolve this by enhancing the gardener/pvc-autoscaler project to reconcile a new PersistentVolumeClaimAutoscaler CustomResourceDefinition which enables declarative autoscaling of PersistentVolumeClaims. The proposal details how the gardener/pvc-autoscaler is deployed in Gardener Seed and runtime clusters to autoscale volumes of observability components (Prometheus, Vali, VictoriaLogs).
Additionally, the proposal goes over some risks about cloud provider limitations related to volume resizing and risks related to how volume metrics are collected. It describes the impact of these risks and presents potential mitigations.
Motivation
Problem Statement
Gardener currently provisions PersistentVolumeClaims (PVCs) for its observability components (Prometheus, Vali, etc.) with fixed, relatively large storage sizes - we operate under tight resource constraints and logging stack PVs default to a static size of 30GB, for ALL Shoot clusters. This one-size-fits-all approach is necessary to accommodate clusters of varying workload intensities, but it leads to significant inefficiencies:
- Under-provisioning risks for growing clusters: Storage requirements grow organically as clusters scale and generate more metrics and logs. Without autoscaling, clusters risk running out of storage, which can lead to data loss, observability gaps, or service disruptions. To prevent this from happening and bringing down the logging stack, older logs are periodically removed. As a result, in some very large or busy clusters, this strategy allows retention of logs only for 2-3 days.
- Over-provisioning for small clusters: A cluster with minimal workloads has the same storage allocation as a large production cluster, however it might operate with just 5-10% of its observability volumes utilized.
- Manual intervention overhead: Currently, storage adjustments require manual intervention and coordination, creating operational burden and delaying response to storage pressure. Additionally, Gardener stakeholders and
Shootowners provision PVCs for their own workload and run into similar inefficiencies when managing a large number of clusters.
Why this matters
Storage costs represent a significant portion of infrastructure expenses, especially at scale. Across hundreds or thousands of Gardener-managed clusters, over-provisioned storage accumulates substantial unnecessary costs. Additionally, the operational overhead of monitoring storage usage and manually resizing PVCs diverts team resources from more valuable work.
More critically, inadequate storage can compromise observability. When Prometheus or Vali runs out of space, teams can lose older observability signals for their clusters and this can make solving issues and creating root cause analyses much harder as crucial logs can get deleted.
A way to resolve these issues is to automatically adapt the size of PVCs to fit the actual usage requirements of each workload.
Who Benefits
- Gardener operators gain automated storage management, reducing manual toil and operational risk while optimizing infrastructure costs across their cluster fleet.
- End users no longer face issues caused by missing observability signals.
- Stakeholders can see reduced cloud spending because of right-sized storage allocation that matches actual usage patterns rather than worst-case scenarios.
Goals
- Enhance the
gardener/pvc-autoscalerproject with a newPersistentVolumeClaimAutoscalerAPI which offers a declarative way to autoscale allPersistentVolumeClaims belonging to a workload controller. - Use a volume utilization threshold based algorithm to determine whether a
PersistentVolumeClaimshould be resized. - Enable or disable volume autoscaling and the deployment of the
gardener/pvc-autoscalercontroller per Gardener runtime andSeedclusters via settings in theSeedandGardenAPIs. - Deploy
PersistentVolumeClaimAutoscalerresources to autoscale volumes of observability components in Gardener runtime andSeedclusters. - If autoscaling is enabled, provision newly created volumes with smaller initial sizes, as long as such reduction does not contradict Gardener's overall reliability goals.
- Add mutating webhooks in provider extensions that modify fields in the
PersistentVolumeClaimAutoscaler, if necessary to adapt them to provider specific requirements. - Expose Prometheus metrics to enable monitoring of autoscaling behavior and alerting when capacity limits are reached.
- Handle provider-specific volume resize failures gracefully, including automated recovery where possible (e.g., restarting workloads when volumes require detachment for resizing).
Non-Goals
- Scaling volumes in
Shootclusters. SupportingShoots is a long-term goal contingent on extending volume metrics availability and experience with autoscalingSeedand runtime components. See Support for Shoot Clusters for future plans. - Automatically scaling down
PersistentVolumeClaims. - Attempting to resize
PersistentVolumeClaimon storage classes that don't support expansion. - Autoscaling ETCD volumes. The ETCD team plans to orchestrate volume management via
gardener/etcd-druid. - Autoscaling triggered by IOPS (Input/Output Operations Per Second) metrics. For now this can be mitigated by creating the volume with a larger initial size.
Proposal
We propose to enhance the existing gardener/pvc-autoscaler project to reconcile a new CustomResourceDefinition (CRD) that enables declarative autoscaling of PersistentVolumeClaims (PVCs).
Core Concept
The autoscaler will introduce a PersistentVolumeClaimAutoscaler CRD (PVCA for short) that allows users to define scaling policies for PVCs associated with workload controllers (e.g., StatefulSets, Deployments, CustomResources like Prometheus and others). The autoscaler will monitor volume usage and automatically adjust PVC sizes based on configurable thresholds and policies.
Example API Design
apiVersion: autoscaling.gardener.cloud/v1alpha1
kind: PersistentVolumeClaimAutoscaler
metadata:
name: prometheus-seed
spec:
targetRef:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
name: seed
volumePolicies:
- maxCapacity: 5Gi
match:
nameRegex: ".*"
scaleUp:
cooldownDuration: 180s
thresholdPercent: 80
stepPercent: 25
minStepAbsolute: 1Gi
resizeStrategy: InPlace | Off
status:
conditions:
- type: Resizing
status: "True"
reason: ResizeInProgress
lastTransitionTime: "2025-08-07T11:59:54Z"
message: |
Some PersistentVolumeClaims are being resized:
- PVC prometheus-seed-1 is being resized due to insufficient inodes.
- type: RecommendationsAvailable
status: "True"
reason: RecommendationsProvided
lastTransitionTime: "2025-08-07T11:59:54Z"
message: Recommendations have been provided for all PersistentVolumeClaims.
volumeRecommendations:
- persistentVolumeClaimName: prometheus-seed-0
usedByPods: ["prometheus-seed-0"]
current:
usedBytesPercentage: 30
usedInodesPercentage: 20
size: 4Gi
target:
size: 4Gi
- persistentVolumeClaimName: prometheus-seed-1
usedByPods: ["prometheus-seed-1"]
current:
usedBytesPercentage: 90
usedInodesPercentage: 70
size: 3Gi
target:
size: 4GiKey Features
Automatic PVC Discovery
The autoscaler will automatically identify PVCs to manage by examining the controller specified in targetRef. This will be achieved by:
- Using the
/scalesubresource to identify pods belonging to the controller, similar to VPA and HPA. - Listing all PVCs that are mounted in the identified pods.
Volume-Specific Policies
The volumePolicies section allows control over specific volumes using regex or selector based matching, enabling different scaling behaviors for different volume types (e.g., data vs. WAL volumes). By default, if no regex or selector is specified, the configurations in the PersistentVolumeClaimAutoscaler resource apply to all PVCs that are identified by the pvc-autoscaler.
Each volumePolicy exposes the following fields:
match.nameRegex: Regex which will be used to match the name of the PVCs for which thisvolumePolicyis used. If this field is omitted, thevolumePolicyis used for all PVCs managed by this PVCA.cooldownDuration: Minimum time that must elapse after a scaling operation before another scaling operation can be triggered for the same PVC. This prevents rapid successive scaling operations and allows time for the system to stabilize after a resize. For example,180s(3 minutes) ensures at least 3 minutes between resize operations.thresholdPercent: The utilization percentage (either disk space or inodes) at which a scaling operation is triggered. For scale-up, when usage exceeds this threshold (e.g.,80%), the autoscaler will initiate a resize operation.stepPercent: The percentage increase applied to the current PVC size during a scale-up operation. For example,25% means the new size will be at least 25% larger than the current size.minStepAbsolute: The minimum absolute storage increase that must be applied during a scaling operation, regardless of thestepPercentcalculation. This ensures meaningful size increases even for smaller volumes. For example,1Giensures at least 1 gigabyte is added.maxCapacity: The maximum allowed size for a PVC. Once this limit is reached, no further scaling will occur.resizeStrategy: Defines how the autoscaler handles the scaling operation.InPlaceis the default strategy and resizes the volume by directly modifying the corresponding PVC.Offdisables scaling.
Observability and Monitoring
The autoscaler exposes Prometheus metrics for monitoring and alerting:
pvc_autoscaler_resized_total- Total number of times a PVC has been resized (labeled by namespace, PVC name and owning PVCA name)pvc_autoscaler_threshold_reached_total- Total number of times the utilization threshold has been reached (labeled by namespace, PVC name, owning PVCA name and reason: space or inodes)pvc_autoscaler_max_capacity_reached_total- Total number of times the max capacity has been reached for a PVC (labeled by namespace, PVC name and owning PVCA name)pvc_autoscaler_skipped_total- Total number of times a PVC has been skipped from reconciliation (labeled by namespace, PVC name, owning PVCA name, and reason)
These metrics enable operators to track autoscaling behavior, evaluate configured thresholds, and set up alerts for when PVCs reach maximum capacity.
More metrics can be added in the future.
Scaling Algorithm
The PVC autoscaler employs a simple threshold-based scaling approach that makes scaling decisions based on current utilization metrics:
Scale-Up Decision Logic
- Query current volume usage (disk space and inodes) metrics:
kubelet_volume_stats_available_bytes- Available bytes on the volumekubelet_volume_stats_capacity_bytes- Total capacity of the volumekubelet_volume_stats_inodes_free- Number of free inodeskubelet_volume_stats_inodes- Total number of inodes
- Calculate current utilization percentage for both space and inodes
- If storage or inodes usage exceeds
thresholdPercent(e.g., 80%), trigger a scale-up operation - Calculate new size:
max(currentSize * (1 + stepPercent/100), currentSize + minStepAbsolute) - Respect cooldown periods to prevent thrashing
- Cap at
maxCapacityfor scaling up
Handling Scale-Up Failures
Generally, scaling up depends on the csi-resizer, and the pvc-autoscaler does not have any direct influence on the actual resize operation - it can only monitor the status of the PVC and modify its .spec.resources.requests.storage fields. Due to this, recovering from resize failures can only be done for a few specific cases described below.
VMs that do not support online volume resizing: Some VMs require the volume to be detached for the resize to complete and the corresponding Pod to be restarted to reinitialize the file system. Whether this case has occurred can be determined from the ControllerResizeError and FileSystemResizePending conditions in the PVC status. See the Cloud Provider Limitations section for Azure for more details on these conditions and the steps that an operator would have to take to complete the resize operation.
The pvc-autoscaler can automate these steps as follows:
- Watch for the
ControllerResizeErrorcondition to be added to the PVC that is being resized, and once that happens, evict the Pod that uses it. Eviction is used so thatPodDisruptionBudgetsare respected and unwanted downtime is avoided. - A mutating webhook, part of the
pvc-autoscaler, adds a scheduling gate to the Pod'sspec.schedulingGates[]field when the Pod is re-created by the corresponding workload controller, if the PVC used by the pod has theControllerResizeErrorcondition and is currently being resized. - The scheduling gate prevents the Pod from being scheduled so that enough time can pass for the
VolumeAttachmentto be deleted by thekube-controller-manager, the volume detached, and then resized. - The
pvc-autoscalerwatches for theFileSystemResizePendingcondition to be added by thekubeletto the PVC. Once that happens, thepvc-autoscalerremoves the scheduling gate from the Pod. This allows the Pod to be scheduled. When the Pod starts and re-mounts the volume, the file system is automatically re-initialized and the resize operation completes.
The current plan is to implement these steps as part of a separate controller in the pvc-autoscaler which will be responsible for evicting affected Pods and removing the scheduling gate once they are ready to be scheduled.
Insufficient cloud provider resources: When a resize fails due to lack of resources on the cloud provider side, the pvc-autoscaler can leverage the Recovery From Volume Expansion Failure feature available in Kubernetes 1.34+. This allows the pvc-autoscaler to set a smaller value for .spec.resources.requests.storage to recover from the failed resize attempt.
Why Downscaling is a Non-Goal
Downscaling PVCs is significantly more complex than upscaling because it requires:
- Safe data migration to smaller volumes.
- Coordination with application downtime or maintenance windows.
- Risk mitigation for potential data loss.
- Downscaling PVCs could result in a size smaller than the one specified in the workload controller that manages the PVC. Depending on the controller, it might try to scale up the PVC back to its original size. This would require a PVC admission controller that applies the recommended value from the
pvc-autoscalerto the.spec.resources.requests.storagefield of PVCs on updates. This could generate a high load depending on the frequency of updates made by the workload controllers. - Downscaling is not supported natively in Kubernetes nor via cloud provider APIs.
- Data migration via VolumeSnapshot does not work as smaller PVCs cannot be created from VolumeSnapshots that were taken from volumes with a larger storage size. This means an external tool (e.g. a pod that runs rsync or some backup-restore functionality similar to
etcd-backup-restore) is required to migrate the data.
For these reasons, the initial version of pvc-autoscaler will focus on the immediate value of preventing storage exhaustion through automated scale-up. We will postpone the implementation of downscaling and potentially only do it if the requirements for it outweigh the downsides.
In the future, the task of downscaling could be implemented as part of a separate controller. The pvc-autoscaler will only be responsible for triggering downscaling and monitoring the status of the operation. One possible approach is to offer a plugin mechanism, allowing stakeholders to write their own downscaling logic which is specific to their application.
A potential future addition to the PVCA API for downscaling could look like this:
spec:
volumePolicies:
- minCapacity: 2Gi
scaleDown:
cooldownDuration: 180s
stabilizationWindowDuration: 3000s
thresholdPercent: 60
stepPercent: 25
minStepAbsolute: 1Gi
resizeStrategy: Rsync | OnVolumeDeletion | OffminCapacity: The minimum allowed size for a PVC. Once this limit is reached, no further downscaling will occur.stabilizationWindowDurationcan be used to specify the duration for which the current usage must be below thethresholdPercentbefore triggering downscaling. The rationale behind this is that downscaling is a disruptive operation which should be avoided during short-term data reductions, e.g. after some compression operation.Rsyncresize strategy indicates that downscaling shall be performed by creating a new smaller volume and using rsync to move data from the current volume to the new one.OnVolumeDeletionresize strategy indicates that PVC is resized only if it was deleted and the backing volume also deleted. This would require a webhook to mutate the PVC on creation.Offdisables downscaling.
PVC Admission Webhook Considerations
An admission webhook for mutating PVCs on creation is not required in the current implementation. Current workload controllers (StatefulSets, Prometheus, VLSingle) do not overwrite PVC storage requests when the pvc-autoscaler has increased them beyond the size specified in the controller.
Additionally, we do not see it as necessary to mutate newly created PVCs when a new replica is created for the workload. In such cases its size will be gradually increased by the pvc-autoscaler as more data is added to it. We assume that the way data is distributed to new replicas is dependent on the workload, e.g. sharding in Prometheus.
An admission component may be needed if downscaling is introduced in the future to prevent workload controllers from increasing the PVC storage requests back to their original size after the pvc-autoscaler has reduced them. The design and implementation of such an admission component will be discussed as a separate proposal once a decision to implement downscaling has been made.
Architecture Overview
The following diagram illustrates the high-level architecture and workflow of the PVC autoscaler:
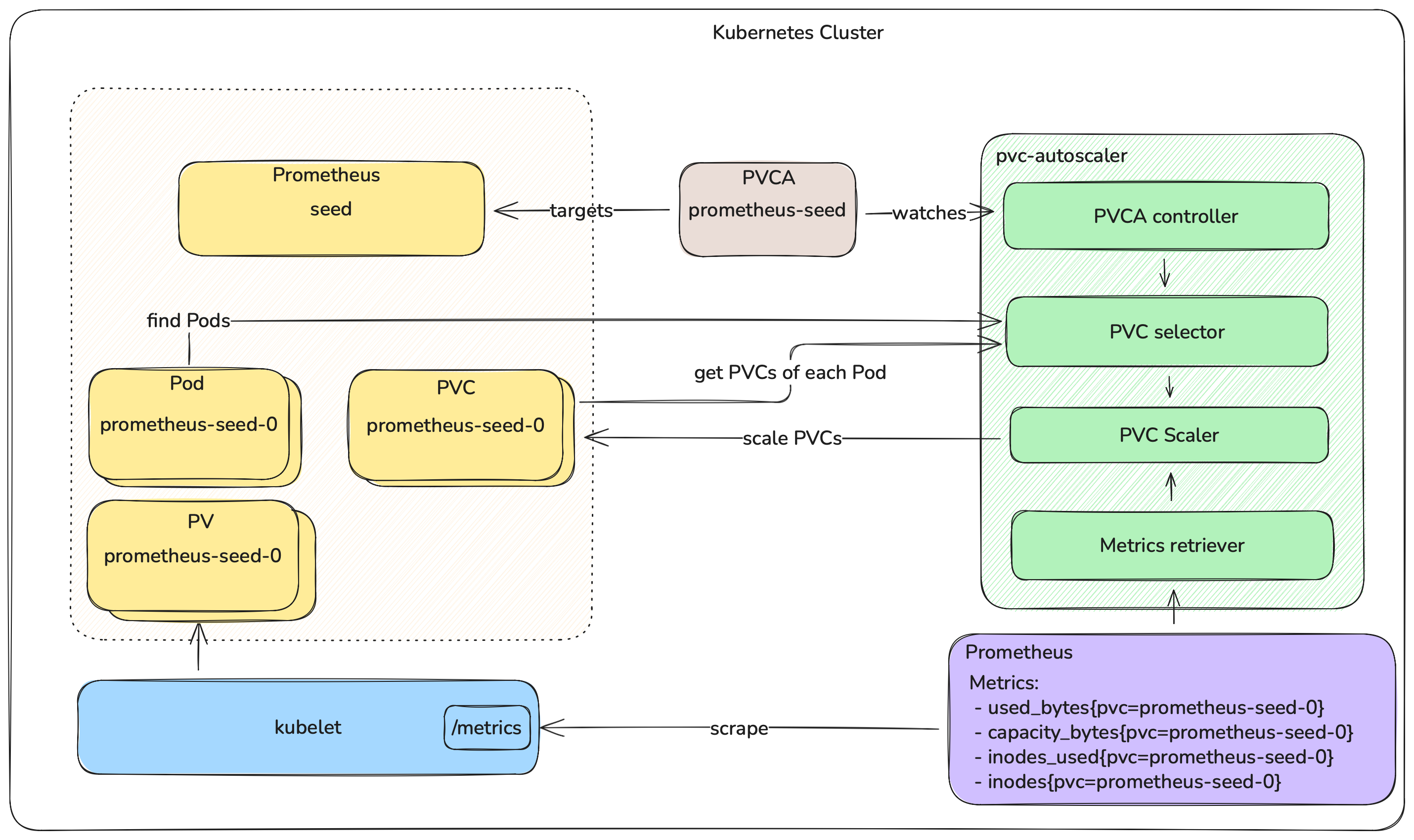
Gardener Integration
Integration Into Seed Clusters
The pvc-autoscaler is integrated into Gardener as a Seed system component, deployed by gardenlet as part of the Seed reconciliation flow. It runs as a Deployment in the Seed's garden namespace. Its primary driving signal is the PVC metrics from the Seed cluster's cache Prometheus instance.
In this initial iteration, pvc-autoscaler scales two categories of Vali and Prometheus volumes: those in Shoot namespaces, and those in the Seed's garden namespace.
The Vali and Prometheus component deployers (part of gardenlet's Shoot reconciliation flow) create PersistentVolumeClaimAutoscaler resources for their respective workloads. The pvc-autoscaler discovers and scales PVCs for both Shoot-level and Seed-level observability components.
The Seed API is extended with a new field - spec.settings.persistentVolumeClaimAutoscaler, which contains settings for the pvc-autoscaler deployed in the Seed.
Proposed change to Seed API:
apiVersion: core.gardener.cloud/v1beta1
kind: Seed
metadata:
name: my-seed
spec:
...
settings:
persistentVolumeClaimAutoscaler:
enabled: trueWhether the pvc-autoscaler is deployed in a Seed cluster is determined by the enabled field. Operators can set this field to true on a seed-by-seed basis for gradual rollout. An API field was chosen instead of a feature gate to cover cases for cloud providers that might not support resizing PVCs.
When pvc-autoscaler is deployed, initial sizes will be reduced from current defaults for newly created volumes. The new sizes will be determined by examining the storage usage of observability components across all current Shoot and Seed clusters. This approach enables efficient resource utilization while allowing growth as needed.
PVC and PVCA resources might have to be created with different values depending on the cloud provider. For example, on AWS volumes can be resized only once per 6 hours (described in more detail in the Cloud Provider Limitations section). This requires that PVCs are created with higher initial storage requests and PVCAs are created with higher values for the spec.volumePolicies[].scaleUp.minStepAbsolute and spec.volumePolicies[].scaleUp.cooldownDuration fields. This will be achieved by implementing provider-specific mutating webhooks for PVCs and PVCAs in the provider extensions.
With this we reduce the API surface and keep provider-specific logic out of core Gardener APIs, reduce operational overhead and achieve proper separation of concerns.
Along this way, the .spec.volumes.minimumSize field in the Seed API will be deprecated and also moved into a provider-specific webhook as well.
Integration into Gardener Runtime Clusters
Similarly to Seed clusters, the pvc-autoscaler is deployed in the Gardener runtime cluster by gardener-operator as part of the Garden reconciliation flow. Its primary driving signal is the PVC metrics from the garden Prometheus instance.
The Garden API is extended with a new field - spec.runtimeCluster.settings.persistentVolumeClaimAutoscaler, which contains settings for the pvc-autoscaler deployed in the Gardener runtime cluster.
Proposed change to Garden API:
apiVersion: operator.gardener.cloud/v1alpha1
kind: Garden
metadata:
name: garden
spec:
...
runtimeCluster:
settings:
persistentVolumeClaimAutoscaler:
enabled: trueSimilarly to Seed clusters, any provider-specific changes to PVCs and PVCAs are handled by corresponding mutating webhooks in the provider extensions.
Support for Shoot Clusters
Autoscaling volumes for Shoot clusters is a non-goal for this proposal because of missing volume metrics in the Shoot's Prometheus instance. Not only that, but Prometheus might not be deployed for Shoot clusters as operators can opt out of it. Additionally, we would like to gain experience with autoscaling volumes in the Gardener runtime and Seed clusters before offering this to stakeholders.
As a long-term goal of adding autoscaling for Shoot clusters after finalizing it for Gardener runtime and Seed clusters, we plan on following up with these steps:
- Propose adding PVC volume metrics (disk space and inode usage) to the Kubernetes
metrics-serverAPI. - Once PVC metrics are available via the standard Metrics API, the autoscaler can be refactored to use the Metrics API instead of Prometheus, removing the dependency on seed-level Prometheus infrastructure.
- With metrics available via the Metrics API, the autoscaler can be deployed for
Shootclusters and scale PVCs for end-user workloads.
Impact and Alternatives
Risks, Downsides and Trade-offs
Metrics used for volume stats are still ALPHA
The metrics used to determine the storage utilization are in ALPHA stage and might change in the future. Tests in the Gardener project were already enhanced to ensure that the metrics required by the pvc-autoscaler are available in the Kubernetes versions supported by Gardener. For more information see the Ensure kubelet volume stats metrics availability PR.
Additionally, the Prometheus queries used by the pvc-autoscaler are configurable via flags, so they can be easily modified by operators if the metrics are changed.
Metrics Sources
The pvc-autoscaler uses Prometheus as its metrics source and queries it for the metrics required by the Scale-Up Decision Logic. Prometheus was chosen because it is already available in Gardener runtime and Seed clusters and already scrapes kubelets for volume metrics. One downside to this approach is that Prometheus becomes a single point of failure, especially when it does not run in high-availability mode or runs out of free space. However, this could be circumvented with proper configuration of the thresholdPercent, minStepAbsolute, and stepPercent fields.
The following alternatives were also considered:
- Kubernetes Metrics API (
metrics-server): Cannot be used currently because it does not expose PVC disk usage metrics. There is no active work to add PVC disk metrics tometrics-serverthat we are aware of, although there have been previous attempts in that direction (e.g., KEP 5105, which was closed, attempted to add PVC metrics support tokubectl topand one of the suggested ways to do that was by enhancing themetrics-serverto provide the necessary information). There seems to be a clear need for such functionality in the community, and we may file a proposal in this direction in the future, especially because this is required for the long-term goal of autoscaling volumes forShootclusters - Direct
kubeletqueries: Volume metrics can be fetched from eachkubelet's/metricsendpoint, either directly or through thekube-apiserverproxy. However, this requires additional logic to discover nodes and proper authentication and authorization, which basically duplicates what Prometheus does. We may still consider this as a fall-back mechanism depending on the availability of Prometheus.
Latency
The pipeline which propagates the volume metrics in Gardener, driving pvc-autoscaler, is as follows:
kubeletcollects PV state data and publishes resource metrics. Default poll interval: 1 minute- The
Seed'scachePrometheus polls the metrics provided bykubelet. Default poll interval: 1 minute. pvc-autoscalerpolls theSeed'scachePrometheus instance. Poll interval: 1 minute.
The reaction time, until pvc-autoscaler initiates a volume resize, can thus exceed 4 minutes. The resize operation itself, including the file system resize, can further take a few minutes. The cumulative delay, roughly estimated to be up to 10-12 minutes, is mitigated via an appropriate safety margin, provided by the choice of utilization level, configured as a scaling trigger threshold.
Cloud Provider Limitations
Different cloud providers impose specific constraints on volume resizing that affect the autoscaler's behavior:
AWS (ebs.csi.aws.com): EBS volumes can only be resized once every 6 hours. This means if multiple scaling events are triggered in rapid succession, subsequent resize operations will fail until this period expires. Failed resize attempts due to this limit are retried in the next reconciliation cycle. PVCA's cooldownDuration, stepPercent and minStepAbsolute have to be configured to larger values to accommodate the less frequent scale-ups.
Azure: Some Azure virtual machine types do not support resizing attached volumes while pods that use them are still running. When a PVC that uses a volume mounted on such a virtual machine is attempted to be resized, the resize operation fails and the ControllerResizeError condition is added to the .status of the PVC:
spec:
resources:
requests:
storage: 20Gi
status:
allocatedResources:
storage: 20Gi
capacity:
storage: 10Gi
conditions:
- lastProbeTime: null
lastTransitionTime: "2025-08-07T11:59:54Z"
message: |-
failed to expand pvc with rpc error: code = Internal desc = failed to resize disk(/subscriptions/<subscription>/resourceGroups/<rg>/providers/Microsoft.Compute/disks/<pv>) with error(PATCH https://management.azure.com/subscriptions/subscription/resourceGroups/<rg>/providers/Microsoft.Compute/disks/<pv>
--------------------------------------------------------------------------------
RESPONSE 409: 409 Conflict
ERROR CODE: OperationNotAllowed
--------------------------------------------------------------------------------
{
"error": {
"code": "OperationNotAllowed",
"message": "Change in disk property of VM of size 'Standard_D4_v3' is not supported."
}
}
--------------------------------------------------------------------------------
)
status: "True"
type: ControllerResizeErrorThe resize must be completed in "offline" mode on the provider side, meaning that the Pod using the PVC has to be deleted and the volume safely detached for resizing.
Afterwards, when the volume has been resized, the FileSystemResizePending condition with status True is added to the .status of the PVC (the ControllerResizeError condition is not mentioned below for brevity):
spec:
resources:
requests:
storage: 20Gi
status:
allocatedResources:
storage: 20Gi
capacity:
storage: 10Gi
conditions:
- lastProbeTime: null
lastTransitionTime: "2025-08-07T12:05:34Z"
message: Waiting for user to (re-)start a pod to finish file system resize of
volume on node.
status: "True"
type: FileSystemResizePendingAt this point, the Pod which uses the PVC can be re-created. Once the Pod starts up and re-mounts the volume, the file system is resized and the full resize operation finishes. The FileSystemResizePending and ControllerResizeError are removed, and the .status.capacity.storage field is updated to the new (scaled-up) value by the kubelet.
Dependency on csi-resizer
As the csi-resizer is a failure point we have no control over, PVC upscaling may fail because of it. In that case there is nothing that can be done to prevent volume exhaustion. Even if the volume is exhausted the worst outcome of it would be:
- For logging - missing old logs
- For metrics - hitting possible issue of Prometheus getting stuck in
CrashLoopBackOff(currently possible due to bug of invalid wal record leading to volume exhaustion ref)
Scaling Algorithm and API Alternatives
VPA's Historical Approach
At first glance, it seems like the PersistentVolumeClaimAutoscaler API should be similar to the VerticalPodAutoscaler (VPA) API as both scale resources vertically. However, VPA is based on a much more complex, harder to reason and debug algorithm which uses historical data, histograms and percentiles, which dictates the way that the VPA API is designed. VPA's recommendation engine analyzes resource usage over time windows, calculates percentiles (typically p95 or p99), and applies sophisticated algorithms to determine resource recommendations.
The main benefit of using histograms is that random spikes of CPU won't trigger unnecessary scaling events. However, disk space consumption does not have random spikes like CPU or memory. Storage usage follows predictable growth patterns.
Example Vali space usage patterns: 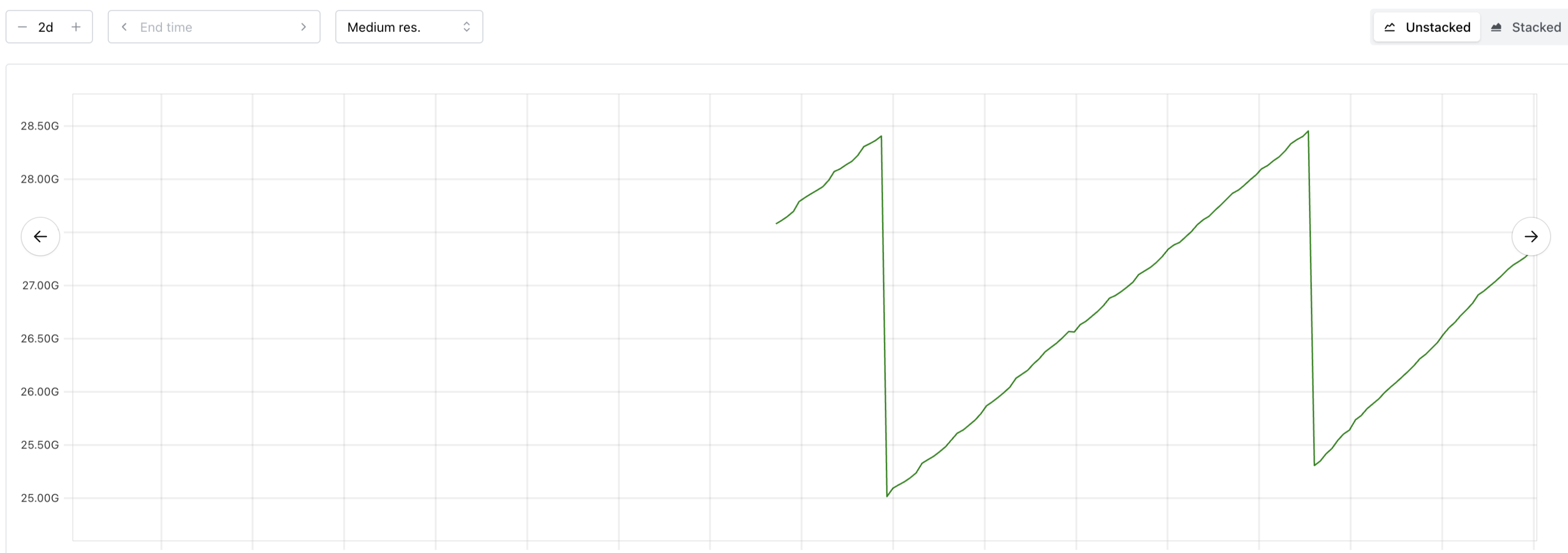
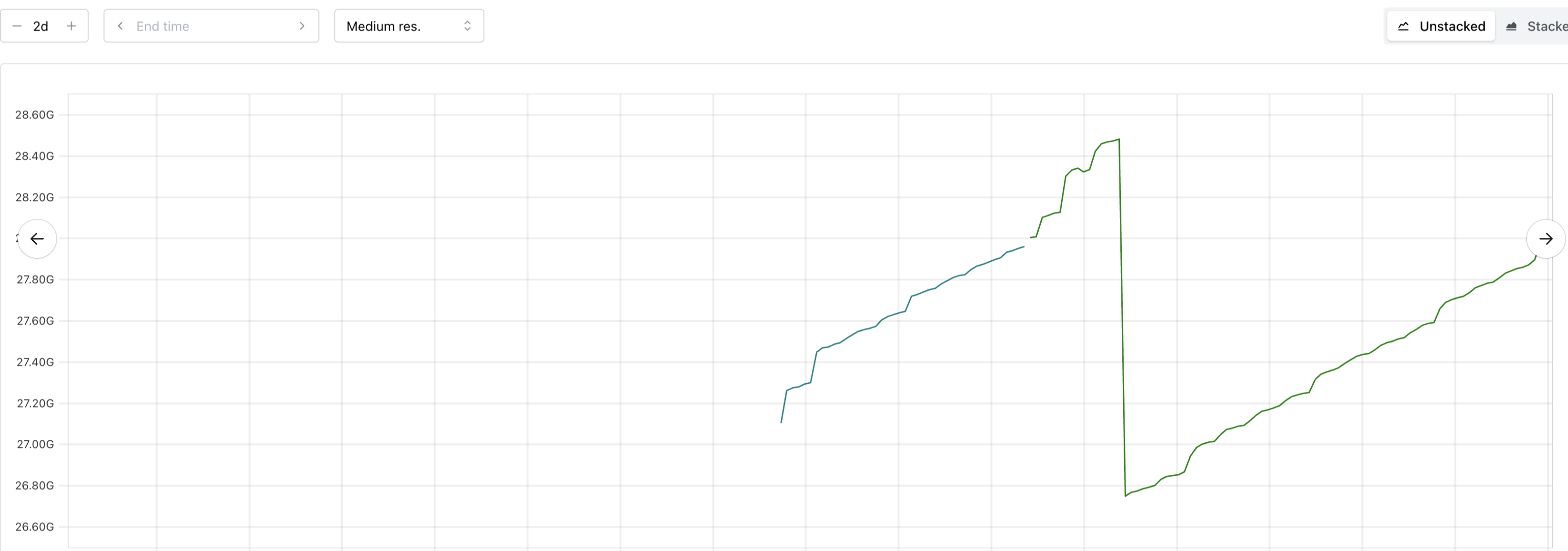 Example Prometheus space usage patterns:
Example Prometheus space usage patterns: 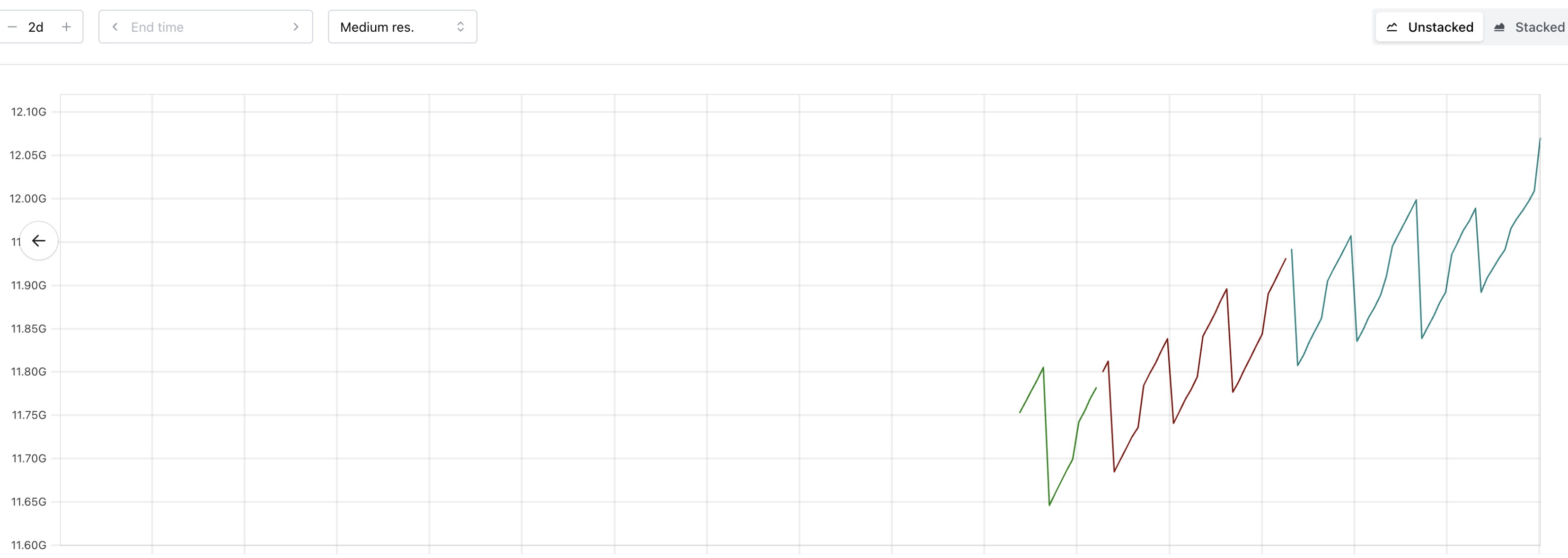
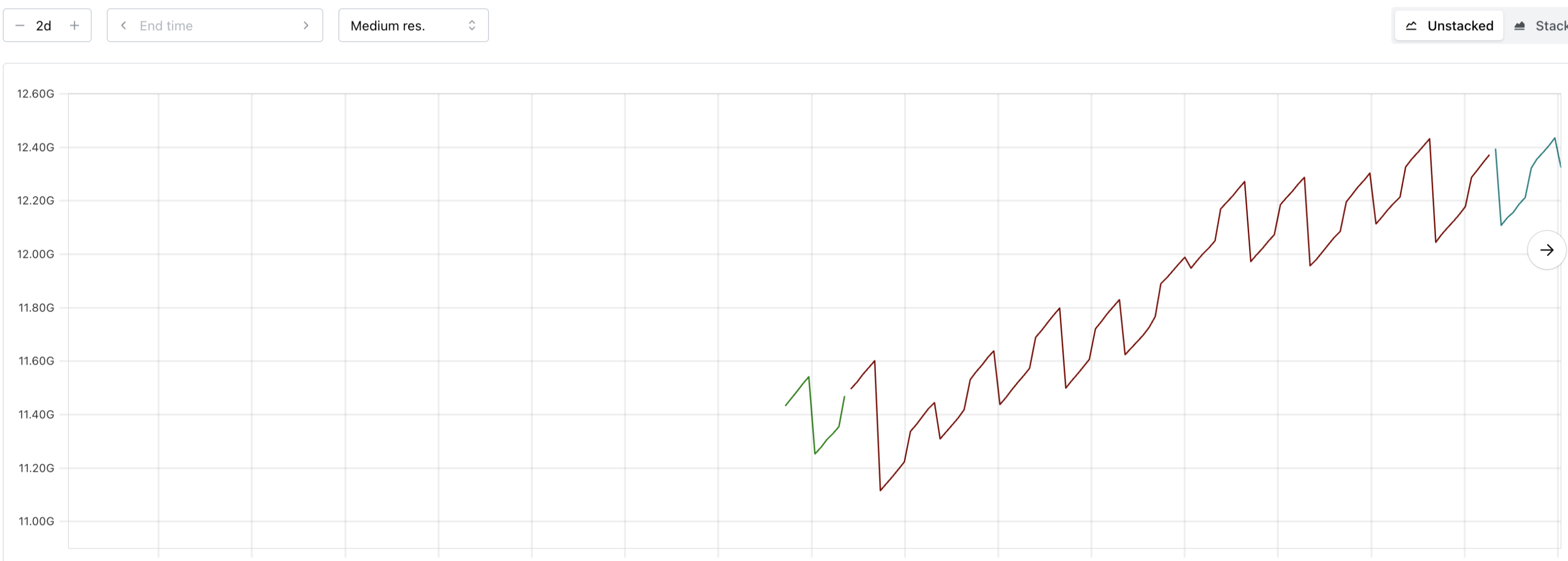
Note that these drops are non-random and caused by periodic compaction or Vali's log cleaner when a certain threshold is reached.
Because observability components follow a predictable semi-linear pattern there is no need for the VPA-like approach.
Trend-Based Algorithm
A trend-based algorithm that calculates the increase of used storage over a given time window and determines how much the PVC has to be scaled up based on that was also considered. However, this could behave unexpectedly for workloads that have periodic data compaction or deletion. The time window could be such that it miscalculates the storage increase or even detects a downward trend due to the compaction. It also adds additional complexity to the controller which does not seem worthwhile.
Gliding Average Algorithm
A gliding average algorithm calculates the average of volume utilization metrics over a sliding time window. The intent is to smooth out short-term fluctuations and prevent scaling decisions based on temporary spikes. Such an algorithm is not suitable to determine whether to resize a PVC, because storage usage usually grows monotonically, unlike CPU or memory which fluctuate. The average value would always lag behind the current utilization, which would introduce additional lag when deciding whether to scale up a volume. The additional complexity required for such an algorithm is not worth it, compared to a simple threshold-based approach.
Gliding Maximum Algorithm
A gliding maximum algorithm tracks the highest utilization value observed within a sliding time window. This approach aims to ensure capacity for the highest observed demand. This is equivalent to the threshold-based algorithm when scaling up storage - since storage grows monotonically, the maximum value over any recent time window is almost always the current value.
Such an algorithm could be valuable to prevent premature downscaling after temporary storage drops (due to compaction or log cleanup). However, downscaling is explicitly a non-goal in this proposal.
A gliding maximum can still be used to calculate the status.current.usedBytesPercentage and status.current.usedInodesPercentage fields in the PVCA API, so that the frequency of updates to the status field is reduced. The size of the sliding window might depend on the workload to effectively reduce the frequency. For now, a 12-hour window seems reasonable, considering available disk usage metrics from Prometheus and Vali. Alternatively, a high water mark could be used, so that only the highest disk utilization ever reached is recorded in the status.
Alternative 3rd Party PVC Autoscalers
The following existing 3rd party PVC autoscalers were evaluated:
Note: The evaluation of each autoscaling option also accounts the scenario of offering PVC autoscaling service to Shoot owners.
Alternative: topolvm/pvc-autoresizer
Overview: An immature solution, closer to the proof-of-concept stage, than to the production-ready stage. Has some core design issues. The project is gaining a bit of traction, possibly because of no good alternatives in the market niche.
Recommendation: To use it, we'd need to become the primary maintainer and rework core logic. However, the existing functionality does not have sufficient critical mass to justify the burden of coordinating with other maintainers. pvc-autoscaler is a better fit for us.
Details:
- Works only on a golden path. Lacks the intermittent fault countermeasures, necessary for reliable operation, e.g:
- Reconciliation is aborted upon first fault, without retrying.
- Silently skips a PVC when any of its metrics is missing - a PVC with exhausted capacity will not be scaled if it is missing an unrelated inode metric.
- Does not emit events to support operating/troubleshooting.
- There is an inherent inefficiency coded in the very core logic, for the case where only a small fraction of PVCs are under scaling.
- On the positive side, the project seems to be gaining a bit of traction, so rough edges will likely be smoothed over time.
Alternative: lorenzophys/pvc-autoscaler
Overview: A decent minimal solution, in early alpha. Lacks some features needed by Gardener. Maintained but no longer actively developed.
Recommendation: From the Gardener perspective, it has no advantages over pvc-autoscaler, which has broader functional support.
Details: The lack of inode scaling, event recorder, and exposed metrics, would mean that we'd need to implement these on our own. The lack of active development means that we would likely need to take over the project completely.
Alternative: DevOps-Nirvana/Kubernetes-Volume-Autoscaler
Overview: An (estimated) early alpha Python implementation. No longer actively developed.
Recommendation: From the Gardener perspective, it has no advantages over pvc-autoscaler.
Details: Uses a custom Prometheus query, which is an interesting approach.
Decision Request
We are seeking approval from the Technical Steering Committee to:
- Approve the proposed API design for the
PersistentVolumeClaimAutoscalerCRD. - Validate the architectural approach including:
- Threshold-based scaling algorithm (vs. historical/percentile, trend-based, gliding maximum and gliding average approaches).
- Automatic PVC discovery from the provided
targetRef. - Integration with
cachePrometheus inSeedclusters. - Integration with
gardenPrometheus in Gardener runtime clusters.
- Agree on the phased implementation approach outlined below.
Proposed Implementation Timeline
Phase 1 (Core Implementation)
- Implement scale-up functionality.
- Support for StatefulSets, Prometheus and VLSingle as the primary use case (observability component PVCs).
- Basic monitoring and status reporting.
- PVC auto-discovery mechanism from the provided
targetRef. - Collect volume stats metrics from Prometheus.
Phase 2 (Gardener Integration)
- Deploy in the
gardennamespace of GardenerSeedclusters where the autoscaler has easy access to volume metrics from thecachePrometheus instance. - Deploy in the
gardennamespace of Gardener runtime clusters and use thegardenPrometheus instance to fetch volume metrics. - Focus is on autoscaling observability component PVCs.
Phase 3 (Future Enhancement)
- Propose enhancing the Kubernetes Metrics API (
metrics-server) to also serve metrics for PVCs. - Extend deployment to Shoot clusters (may require different metrics access patterns).
- If necessary, collect volume stats metrics from other sources.
- Enable
Shootowners to use the autoscaler for their own workloads.
Phase 4 (If required by stakeholders)
- Extend the API with scale-down capabilities (requires complex data migration strategies like rsync-based data migration). Will only be implemented if demand is high enough and outweighs the downsides.
- The scale-down itself will be handled by a separate controller or plugin.
Next Steps
Upon approval, the team will:
- Finalize the CRD API specification based on committee feedback.
- Implement Phase 1 features.
- Document configuration and operational guidelines.
- Integrate the
pvc-autoscalerin Gardener (Phase 2). - Phase 3 and Phase 4 to be tracked as separate proposals.
Appendix
How PVCs are managed by workload controllers
As part of the work on the new pvc-autoscaler API we also checked whether the resized PVCs would get overwritten by the workload controllers that manage them or whether they would run into an error state if the storage size specified in the workload controller is smaller than the one in the corresponding PVCs. For that we checked StatefulSets, Prometheus and VLSingle controllers. These are the main scaling targets when integrating pvc-autoscaler in Gardener.
StatefulSets
StatefulSets allow users to specify volumeClaimTemplates from which PVCs are created. The volumeClaimTemplates are immutable and the StatefulSet controller does not modify PVCs after they have been created. KEP 4651 makes volumeClaimTemplates mutable, however one of the goals of the authors is that if the PVCs were already scaled up, their size will not be touched by the StatefulSet controller.
Prometheus
Prometheus instances create a StatefulSet and the same as above applies.
VLSingle
According to GEP 35 the VLSingle controller will be used to manage a VictoriaLogs instance in the near future. VLSingle creates a Deployment and a PVC with the storage size specified in the VLSingle resource. If the PVC's size is scaled up and ends up being bigger than what is specified in the VLSingle resource, the controller continues to behave normally. If the PVC's size is scaled down and is smaller than what is specified in the VLSingle resource, the controller responsible for VLSingle scales up the PVC to match the size in the VLSingle resource.